
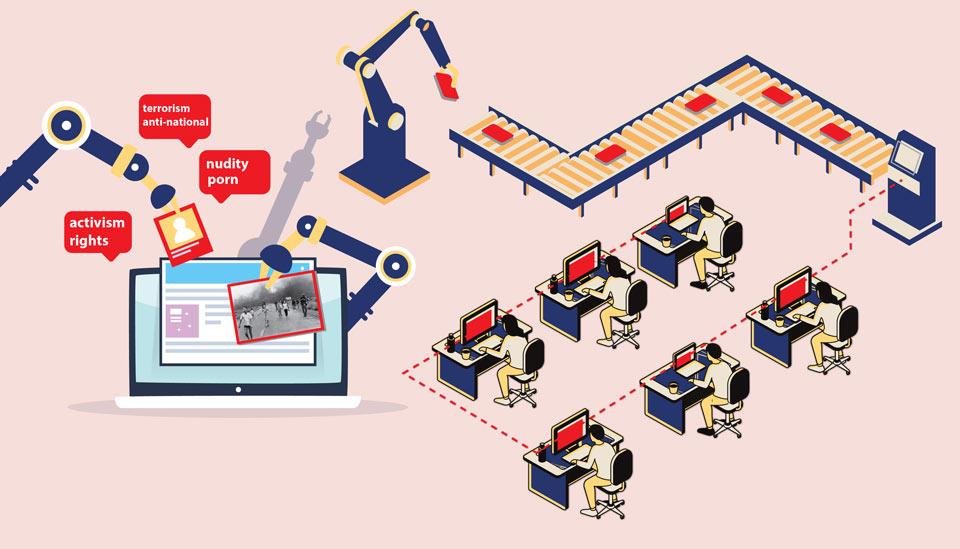
Image description: People working at separate desks on screens that are fed onto an assembly line, leading to a large screen. Illustration by Paru Ramesh.
Content moderation online is currently done by most social media companies through a mix of automation (or what is sometimes referred to as artificial intelligence or AI) and human moderators. Automation deals effectively with certain kinds of content such as sexually explicit images, child pornography, terrorism-related content – but it is not a foolproof system. Here human intervention and oversight are needed, especially when it comes to the meaning of what is being said in comments or conversations online.
What is becoming increasingly evident is that the choice is not between the alleged neutrality of the impersonal machine and the errors and finiteness of human moderation, as both work in tandem.
The choices are not between the alleged neutrality of the impersonal machine and the errors and finiteness of human moderation, as both work in tandem
Perspectives on the use of AI and humans in content moderation
“Cheap female labour is the engine that powers the internet” - Lisa Nakamura
“… social media platforms are already highly regulated, albeit rarely in such a way that can be satisfactory to all.” - Sarah Roberts
What makes any content platform viable is directly linked to the question of what makes you viable as content. Sarah Roberts, through a series of articles, shows how the moderation practices of social media giants all operate in accordance with a complex web of nebulous rules and procedural opacity. Roberts describes content moderation as dealing with “digital detritus”1 and also compares cleaning up the social media feed with how garbage is dumped by high-income countries on low- and middle-income countries (for instance, the dumping of shipping containers full of garbage by Canada onto the Philippines).2 She adds that there has been "significant equivocation regarding which practices may be automated through artificial intelligence, filters and others kinds of computational mechanisms versus what portion of the tasks are the responsibility of human professionals." Roberts also adds that in May 2017, Facebook added 3,000 moderators to its global workforce of 4,500 already.
For commercial content moderation to be effective, the level of knowledge expected of the person doing it is quite high – ranging from knowledge of the language, context, but also the relevant laws and the platform guidelines and norms. Additionally, this work “calls for laborers to be immersed in a flow of digital detritus” and what eventually will be the ramifications of that.
Companies emphasise or de-emphasise the role of automation depending on the public image they want to present, and as raised by Lily Irani, “what is at stake in hiding the delivery people, stockroom workers, content moderators, and call-center operators laboring to produce the automated experience?”3 There is an expectation that a certain kind of menial work can be done by computers already, but this is not the case – we still need people to listen and transcribe audio correctly, to sift through content and make decisions, to do copyediting accurately, and so on. Irani sketches a possible vision of the future where humans and computers working together is an ethical project where the humans (and here obviously we mean workers) are valued. Shouldn’t we be building AI that improves the lives of workers, rather than AI that is replacing them? 4
The nature of content we find online is determined by a complex socio-technical assemblage that is driven largely by the logic of profit and brand management. Lisa Nakamura explores how moderation is also done by users of platforms themselves. She points to the “hidden and often-stigmatised and dangerous labour performed by women of colour, queer and trans people, and racial minorities who call out, educate, protest, and design around toxic social environments in digital media.”5 Curiously, this analysis in 2015 predates the massive call-out of male entitlement and harassment via #metoo and its various variants in entertainment, workplaces, media, academia, sports, civil society, etc.6 This labour to point out racism, sexism and misogyny online all goes towards making the platform a safer space eventually, and Nakamura also points out how all this “guerilla moderation” and labour (advice on correct terminology, free guides, documentation, etc.) ultimately is feminised, devalued, “offshored for pay and borne by volunteers.” Nowadays this would even include dealing with disinformation and fake accounts7, which raises the question, what are the platforms even doing in these instances?
This labour to point out racism, sexism and misogyny online all goes towards making the platform a safer space eventually
This voluntary form of content moderation against harassment and abuse can be traced back to the early days of the internet – in the spaces of the AOL chat and the excess of unpaid and guerrilla, uncoordinated moderation by almost 14,000 people who were community managers.8 Nakamura draws a broader link also to how women’s work, especially unpaid domestic labour, immaterial labour and affective labour has historically been unpaid, even if it is essential for the reproduction of the workforce, maintenance of family structures etc. all of which capitalism as a system is reliant on.
It is troubling that a lot of the incredibly powerful speech against casteism, racism and sexism online that builds collective resistance and unseats the privileged, is unpaid labour in the service of social media companies. Instances of such work would include, for instance, exposing embedded misogyny, educating people on what is okay to say and not, pointing out misgendering and instances of deadnaming, arguing how certain words and sentiments are racist and casteist etc. This is now (hyper)vigilance and work that is expected from those already marginalised to constantly direct and redirect how the conversations should go. Added to this is that historically and even in the present, exploitative work relies on structures such as caste, slavery, racism, gender, or the precarity of migrant populations.
The cycle seems to be how affective voluntary work that makes a community space safe, instead of being recognised as valuable and worthy of compensation, becomes feminised and devalued. Even if eventually it becomes recognised as work, it is then “offshored” and done by workers in middle- and low-income countries, especially those who have inherited and mastered languages such as English, allowing them to be competent moderators. Many have pointed out how a lot of the nimble work that goes into making computers and devices is also feminised labour, and largely women are employed as semi-conductor workers, workers in the fabrication laboratories and electronic assembly plants in East Asia.9 In her talk, Nakamura says that this labour is about assessing feelings – will a person be “hurt, pained, repelled, horrified” by what they see online. It is basically affective (and feminised) labour of recognising how a word/image online can make you feel – is it arousing, repulsive? Does it disgust you? Make you feel ashamed?
Now at least part of this moderation is being done and potentially could largely be done through automation, though this is not a direct replacement for human labour, in the sense that both aspects would work together. What we have to keep in mind, from the perspective of the user, is that automation does not cleanly remove the assumptions on the basis of which humans make faulty decisions, but it, in fact, codifies them. Algorithms are pieces of software within which decisions and biases by people are still embedded, and moreover, these biases are relearned through training and use on platforms.10 Technologists, programmers and designers play a huge role, which is why we need principles around design and technology justice. With regard to this, Sasha Constanza Chock writes - “ Most design processes today are therefore structured in ways that make it impossible to see, engage with, account for, or attempt to remedy the unequal distribution of benefits and burdens that they reproduce.”11 At the massive scale at which content moderation is taking place currently, automation is a blunter version of human-decision making that reverses none of the biases, and historically humanity has aggregated enough structural inequality, discrimination and violence that that history stains everything.
Image description: Note G in appendix to the Analytical Engine written by Ada Lovelace, also referred to as the first computer program and algorithm detailing "complete simultaneous view of all the successive changes". Source: How Ada Lovelace’s notes on the Analytical Engine created the first computer program
The emotive uses of AI: Automating language
In a story by Roald Dahl (that I remember reading in my tweens), he suggests that a machine would write stories in the future – a machine that is called The Great Automatic Grammatizator, because all that is needed is a memory for words and for plots. This is hardly a futuristic project alone now as AI could be used to write novels.
What algorithms and machines are capable of doing (even if as per the popular mythology of Blade Runner they cannot feel) is to break down, re-assemble and “understand” language, especially English though this would not apply so easily to other languages (the first line of defence against Alexa has to be local languages which completely befuddles her). One instance from the contemporary which shows how language can be depolyed through automated tools is how people enter into conversations with AI therapy bots and somehow this simulated conversation does address their/our anxiety, panic or depression. The affective uses of AI can range from companionship for the elderly to addictive voice assistants, from sex robots to story tellers. Maya Ganesh explores what is happening in this space of emotive connections through and via AI and our relations to robots as similar to how we relate with pets, children or “almost-humans”.12
A potentially interesting way of dealing with content moderation is not at the point of removal and cleaning, but as suggestions and conversations with the user. This would work similarly to the AI therapy bots simulating a conversation, and here you ask yourself whether you should post something or not or are given suggestions to word it less aggressively. One such project is Perspective from Google, which provides an API for moderating content that uses deep learning to score how offensive your post could be (and the API could also be used by moderators). Is this an insidious mode of behaviour modification or censorship? But even before addressing that question, this method would still face the same problem as automation does with content moderation – the inability to read tone in language or to be privy to internal conversations within a clique or group. Would such a tool understand the difference between a private Finsta and your “real” Instagram account? Would it, in fact, stop a brave voice that could potentially begin something like #metoo?
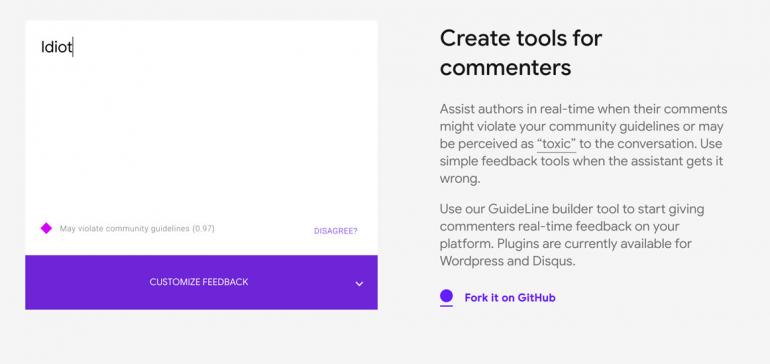
Screenshot of Perspective API for real-time response. I repeatedly have started responding to people who have what I think of as an irrational and ahistorical take on struggles and issues with one word - idiot. So this was the first word I tested on the Perspective API.
Along with the digital divide along lines of gender, class, race, caste and urban-rural, there is also what is often termed as digital literacy. The term seems farcical because even the youngest of children in a village in Karnataka seems to know how to operate a mobile phone camera, but perhaps the problem is not so much literacy as information asymmetry, i.e. what we are not allowed to know. Algorithms are the black box and "the new digital literacy is not using a computer or being on the internet, but understanding and evaluating the consequences of an always-plugged-in lifestyle." Information asymmetry is also how a company like Uber controls the drivers working for them: they know less of how the algorithms work, how the platform organises them, than even perhaps the person who uses the ride-hailing app to get a ride, and far less than the company itself. The laws in the European Union insist that people have a “right to explanation” for the criteria that are being used to evaluate them; that algorithms used in AI are fair, transparent, accountable and even interpretable or that they make sense to us.
The problem is not so much literacy as information asymmetry, i.e. what we are not allowed to know. Algorithms are the black box and "the new digital literacy is not using a computer or being on the internet, but understanding and evaluating the consequences of an always-plugged-in lifestyle."
When it comes to content moderation by social media companies, it is in the interest of the company to effectively moderate content, to ensure that the user experience is not marred by violent and unnecessary sexual content, or that they face so much abuse and harassment that they leave the platform. For once, it is not an entirely uphill battle when it comes to users’ safety, especially when talking about online gender-based violence. But there is an uncomfortable feeling, where your safety and comfort are also the bottom line of the company’s profitability.
What the transparency reports of different platforms tell us (Reports for 2018)
The following examination of transparency reports is based largely on reports from YouTube13(or Google), Facebook14, Twitter in late 2018 and some from 2019. Transparency reports were not the norm, and the first community standards enforcement report from Facebook happened in May 2018, and since then until mid-2019 there have been three transparency reports. The Twitter transparency report has been around since 2012, and they now state their commitment to the Santa Clara Principles on Transparency and Accountability in Content Moderation.
Most social media companies rely on a mix of automated and human moderation for their content, and in all the reports it is increasingly clear that user flagging is often quite low (in the case of Facebook it is mostly less than 5%). Prior to reading transparency reports in detail, I had assumed that a large amount of the removals are based on what users themselves have flagged, but this is obviously not the case.
Sexual or pornographic content, or the terror of (automated) error
Automation is considered more effective in relation to violent and graphic or sexual content. On Facebook, previously 25% of such content was detected by user flags or human moderation and now this percentage in relation to the total amount that is removed has been reduced to 3%. A few years ago Facebook was embroiled in a controversy over the removal of the familiar Viet Nam-era photo “The Terror of War” as pornographic, where the contested image is that of the Vietnamese girl running from Napalm bombs dropping. The quandary posed by using automation is that an obvious decision like whether the above-mentioned image or an ordinary breast-feeding pic is pornographic is easy for a human to determine, but not so easy to figure out using AI.
In relation to the Viet Nam war photo, Roberts describes what Facebook does as a form of commodity control and how it can only view what people say and do and post online through the lens of commodification. She says, “It is this logic that takes a picture of a female child whose skin has been burned off by napalm and categorizes it as child pornography; the harm is not the violence being done to the child (and all children) through war, but in the naked form captured in the photo-as-commodity – in the language of platforms, the “content” – which circulates in order to garner views, participation and advertising revenue for the platforms, and this image does not fit.”
Automation does most of the heavy lifting in relation to images and video, as opposed to text. Of the 8,765,783 videos removed by YouTube in the period of two months from October to December 2018, around 71% of the videos were removed by automated flagging and only about 6.8% were flagged by the ordinary user. About 73% of the automatically flagged videos on YouTube were removed before any views.15
"This image does not fit."
This impressive figure for removal before views is probably because of a number of factors – it is relatively easier to detect and remove all videos with nudity (as opposed to a platform that might allow some) and also, in particular, there is a system in place to deal with child sexual imagery specifically on most platforms. YouTube has created proprietary technology called CSAI Match to detect CSAI (child sexual abuse imagery) and this is mostly based on finding images and videos that match what is the largest existing database of known content, to ensure that the same material does not circulate. The content is hashed – i.e. given a unique digital fingerprint – and used to detect matching content, and similar software is used by a number of companies, including Facebook, which also extended the use to non-consensual intimate images i.e. videos and images made without the consent of both parties, or circulated without consent.
In the 2018 report, Youtube highlights how automated flagging has particularly been effective in dealing with violent extremism, and over 90% of videos that were flagged as such have fewer than 10 views. Terrorist content as well is ususally detected based on digital fingerprints. There are databases and projects such as Jihadology.net that are collecting mostly material from ISIS and flagging it.
Bullying, harassment, hate speech: what automation can’t compute
When it comes to bullying and harassment, this is when the detection technology is not effective: only 14.9% was flagged by Facebook (whether through their tech or their human moderators is not entirely clear), while almost 85% was flagged by users themselves. Facebook says that they are keen on “optimizing (our) proactive detection." Textual content, which is context-based, often reliant on language, culture, tone, personalities and embedded in existing relations, is relatively harder to detect.16 This definitely includes bullying, harassment or what is more colloquially called trolling.
On Youtube, 99.5% of the comments that violate their standards are automatically flagged and 0.5% flagged by humans. The country that flags the most (ahem, no surprise here) is India, followed by the United States and Brazil. These are all countries in which the right wing and fascist parties are in power and deploy people in the digital realm directly and indirectly quite effectively to produce nationalist and misogynist rhetoric.17
The Data and Society study describes content moderation done by large companies as industrial as opposed to community-reliant (which relies on volunteers or user flags) or the artisanal approach where there is case-by-case governance. In the Data and Society study, Caplan shares an anonymised response by one person working in a platform company, who says that the goal in large social media companies is to create a decision factory that ressembles a Toyota factory more than an actual courtroom.18 By using automation, as is used for spam, malware, child pornography – the process of adjudication of content is being routinised rather than problematised.
The Facebook report suggests that Facebook is effective at detecting fake accounts, but only half-way effective with hate speech (though still better than with bullying or harassment). However, as we increasingly know, fake accounts and hate speech are increasingly inter-connected phenomena where armies of real and fake accounts spread malicious and false information about specific groups of people.
Comparing the 2018 Facebook statistics on hate speech to 2017 indicates that the detection technology is getting more proactive and efficient at finding hate speech, and then placing it before human reviewers to determine if it fits their criteria, though the statistics don’t indicate whether the decisions that were made were correct or accurate. Significantly, in late 2017, over 70% of hate speech slurs were reported by users first and in July-September 2018 it was around 46%, which implies over 50% was automatically detected. Twitter too has been getting substantial feedback and criticism that in spite of its allegedly more progressive stance, it is a difficult space for minorities to occupy. This is definitely the opinion of particular groups like Glitch and was also stated in the recent report by Amnesty International titled Toxic Twitter.
Company processes for removal of content remain largely opaque, even if one can argue that company standards are probably more open and progressive in relation to certain kinds of material, for instance around sexuality, considering that there are some countries in the Middle East, Asia and Africa where homosexuality is still illegal. The United Nations has put in place the Guiding Principles on Business and Human Rights aka the Ruggie framework 19, which are non-binding guidelines for business to make sure they operate and respect internationally recognised human rights. The Special Rapporteur for freedom of opinion and expression, David Kaye had done a thematic report on freedom of expression in 201820 and included concerns around company regulation of content. He also wrote about the need for standards for content moderation21 and says - “So to bring back the question at the center of the debate over online speech: Who is in charge?” Kaye urges companies to make human rights law the explicit standard for content moderation.
“So to bring back the question at the center of the debate over online speech: Who is in charge?”
These moves by various bodies indicate a growing realisation that what we have here is a parallel adjudicating mechanism, not one that is particularly responsive to an existing international or national legal or policy mechanism. And this mechanism is reliant on several factors: algorithms or automation and machine-learning, demands of efficiency and profit, the market logic and branding, corporate ideologies, relations between company and state, and so on.
We also should be aware that these companies are adaptable and amenable, especially for the purpose of keeping users and a healthy bottom line, but this also means that they are very rarely immediately transparent. Internal policies for content, accountability, adjudication may have shifted since their last transparency report, and even if they haven't there is no actual way of knowing. The real black box here is the company, not so much knowing how the algorithm works or digital literacy.
Fake accounts and disinformation campaigns
A recent article by Rachelle Hampton shows how black feminists discovered in 2016 that the alt right was using a concerted disinformation campaign to discredit them. The campaign was #EndFathersDay and seemed to be the voice of disgruntled black women and militant feminists attacking men, relying on suspiciously racist tropes and using “a version of African American Vernacular English that no real black person had ever used.” Of course, these were mostly fake accounts, with handles like “@NayNayCantStop, @LatrineWatts, and @CisHate, and bios like ‘Queer + black + angry’ … They dropped words like intersectional and patriarchy.”22
There have also been major instances of keyword squatting and manipulation campaigns related to Black Lives Matter and the 2016 USA elections that were created by a Russian troll farm. This included a fake Facebook page Blacktivist with over 700k likes and this page was repeatedly flagged by activists from Black Lives Matter as fake but was not taken down by Facebook.23 There is organised trolling as discussed in Swati Chaturvedi's book "I am a troll" that tries to go behind the smoothened out facade of the right wing in India24 – here there are internet shakhas (cells) and also “forty-rupee tweets” or paid-for tweets that attack the opponents of Narendra Modi.
One of the things that automation is precisely supposed to be effective with is finding fake accounts and message automation (based on message timing, spam behaviour, use of language, etc.).25 The entire charade of #EndFathersDay effectively mocked woke politics and slandered it. In her article Hampton tracks how several women, including Shafiqah Hudson and others, started tagging what they believed were fake accounts (which often used photographs of black women celebrities as profile pics) and malicious tweets that were masquerading as black women, using the tag #YourSlipIsShowing. About how # YourSlipIsShowing simply gained traction on its own, Shafiqah Hudson says, "That’s the kind of world I want to live in, where you can combat true maliciousness and racism and ick with good manners and good humor.”
Have you been called a troll?
The simplest definition of a troll is someone who wants to offend people online. The Global Assessment of Internet Trolling or GAIT looks at what potentially could be the thrill of trolling: “sadism, psychopathy, and Machiavellianism.”26 Successful trolling is “replacing a factual (or at least civilized) online discussion with a heated emotional debate with strongly emotional arguments.” This can have enormous potential use, especially in the context of political issues and elections, but also is often seen in relation to women, LGBTQIA issues, gender roles and expression, and so on. Most recently are the heated debates around Kashmir – here a facts-based debate quickly devolves into heated and emotional rhetoric.
There have been several accounts of people who felt they had been treated as trolls by the platform itself. One of the ways in which content can get obscured on Twitter and Facebook is where the link in a tweet is replaced by a message that says the material is potentially offensive or disturbing. Often, before people are able to address the many ways in which they get attacked, they themselves get designated as “trolls” or are accused of violating the policy on sensitive media or graphic or adult content, using hateful language, and often of having shared terrorist content. There is a need for studies that explore whose content is being censored or obscured, and for that, there needs to be greater transparency in how content moderation takes place.
For the average user like myself, it often seems like most social media companies get it wrong far more often than right – and often those using social media for political or radical speech that runs counter to the mainstream are the ones who get shut down. Going back to Roberts who analysed the removal of the photograph from the Viet Nam war, she points out how it is those from marginalised identities that face a larger proportion of deletion, erasure and removal. Roberts says, “But in such cases, while removals may be tangible to individual users on a case-by-case basis, they are typically not understood by those same users as systemic and structural, nor as responding to codified policies and practices designed ultimately for brand protection and to serve the demand for revenue generation from advertising.”27
When Sanghapali Aruna posed for a photograph with Twitter’s CEO in November 2018 and he ended up holding a contemporary Dalit poster that said “Smash Brahmanical Patriarchy” she probably didn’t expect the scale of backlash against the words on the poster. The photograph was taken at a meeting where, as Sanghapali writes, the objective was “to discuss our experience of using Twitter, as journalists, activists, women and minorities, and raise issues related to the routine harassment and trolling we face on the platform.”28 Yet it was the photograph from this meeting that led to a fresh round of harassment and abuse that was directed at several women in the photograph and calling out of Twitter for their tacit support. The attacks were casteist and yet had the audacity to imply that what this photograph had done was to target a specific community and that it was hate speech. About this harassment, Sanghapali says, “it is well known that to those who are privileged, equity feels like oppression and that is the only explanation for the outrage we are witnessing on Twitter today.”
In December of 2018, a relatively small controversy blew up in Indian Twitter over a book that was unethically researched and about the lives of trans men in the Indian territory. The book is a gem of what not to do when writing about the lives of others whom we don't entirely understand and see through the fog of our own assumptions and trivial fears. Various articles too addressed the ethics of the research practices, the invasive and presumptuous portrayal and representation of lives of transgender people.29 At various points, people including myself who objected to the book were referred to as trolls. There was an attempt to make lines clear – who can write, who can speak for the other, who can have an opinion. Vijeta Kumar connected the debate on the aforementioned book to her experience as a teacher in a journalism and writing course, and pointed out how many of these writings and “research” about the other are a lackadaisical extension of privilege. For calling out specific people in her article, she too was attacked online, and then threatened with legal action and every other tool in the arsenal of caste privilege. And of course, called a troll.
About being called a troll, Vijeta Kumar says it was not particularly insulting, “at least (she) should have added another word, maybe an adjective.” In many of the debates around trolling it seems the question often is – who trolled first. Kumar’s own assessment of the debate that ensued after her piece was that she was seen as trolling those with upper-caste and savarna privilege through her article.30
In many of the debates around trolling it seems the question often is – who trolled first. Kumar’s own assessment of the debate that ensued after her piece was that she was seen as trolling those with upper-caste and savarna privilege through her article
Reporters from a magazine operating in rural and semi-urban parts of north India called Khabar Lahariya31 presented a paper about trolls at the Imagine a Feminist Internet research conference. In this talk, they spoke of the use of the internet for news and discussion by the women reporters on the team and what relations it alters and configures. One important realisation they had through their work was that the troll is not necessarily an unfriendly figure – the trolls could potentially be a substantial portion of their audience whom they have to work with, and even their die-hard fan.
Between the people who self-identify as trolls and those who see it as useful to engage with trolls, the question is who is this entity then?
Trolls can be either humans or bots or a combination of both; they can be people who are overwhelmingly passionate and unaware of the consequences of what they say or those who are deliberately derailing debates and are paid to do so. The internet with its rhizomatic, non-hierarchical structure is the ideal environment within which trolling can happen, and while it is possible to determine through analysis who are the humans and who are the bots or cyborgs online, the active participation of people is often needed to separate the noise generated by bots and actual debate outside of disinformation tactics.32
An understanding of trolling as a technique of being anti-authority and deliberately disruptive rather than a troll as a person, allows us to see how it is used in various ways, and often also as a reaction to trolling itself. As is evident from the transparency reports, automation tools cannot yet understand human speech in its entirety. It cannot figure out who are the trolls online pushing against what is unsayable and yet true, and who are the trolls that are being deployed directly or indirectly to do undermine debates and to engage in hateful speech and violence against specific people or groups.
What is the ideology of content moderation?
Let’s look more closely at the figures from Facebook for the first quarter of 2019 (January to March) when 19.4 million pieces of content were acted on, and 96.8% of these removed before any ordinary person on Facebook even saw them. This indicates a hugely active mechanism of both automation and human moderation working in tandem, and only 2.1 million of those pieces of content led to an appeal by a Facebook user.
But let’s also look again at our language and the shift in relation to how we understand the disappearance of images, words and text. In relation to the disappearance of the image in cinema, or rather the appearance of a black screen in the early years of cinema, Annette Kuhn, cinema historian and theorist, points out that this is not merely a negative space or an excision, but that censorship is always productive.33 It produces (by removing and stitching together) ideology – and through a reading of what is censored and what remains, we can discern what that ideology is. In most instances, especially when it came to the removal of salacious images of white women before brown audiences in the colony, it was about preserving the image and majesty of the empire.34 Later in post-independence India, it was about promoting the nation and idea of India, but with many formal and informal mechanisms35 (such as no images of kissing or scenes in private spaces like bedrooms for couples, or the depiction of largely savarna people in films) it was also about a continued adherence to strict gender norms, compulsory heterosexuality, family and caste-based kinship.
Facebook has reversed their decision of removing 2.1 million pieces of content, but what is the reasoning, where are the texts of decisions that show how this reversal took place? The flawed, paranoid reasoning of the state was evident in the lengthy judgments on obscenity,36 on computer networks and terrorism, on videotapes and piracy.37 Without the legal archive of judgments, legislations, debates, what do we have to rely on or understand what content moderation is producing, as opposed to the simpler question to answer of what it is removing, which also we don’t quite accurately know. We are left with a list of figures and percentages that indicate how much and how often, but not what.
Yet it is obvious that no statistics on censorship prior to this are even comparable. What would the 19.4 million pieces of content that Facebook removed be equivalent to – one raunchy suggestive Bollywood song where two women interact with each other38, one scene from Lady Chatterley’s Lover by D.H. Lawrence which is the case that laid down the standards for judging obscenity in India. A close reading of that judgment (and the book) reveals that the judicial discomfort originates not simply from the few veiled instances of alleged obscenity in the text, but also because it portrayed a relationship between a working-class man and a “gentlewoman”.39
What would the 19.4 million pieces of content that Facebook removed be equivalent to – one raunchy suggestive Bollywood song?
Since the scale of moderation is massive, the industry would have us believe that what they do is no longer censorship. It is merely good business, keeping the sidewalks clean so you can walk through. As stated by Shorey and Howard – “The methods that fuel these computational processes often remain in the hands of private companies, inaccessible to researchers or the broader public. In light of these processes’ widespread impact and opacity, there is a need for transparency and regulation of algorithms.”40 Since the recent official inquiries into the role of platforms in election meddling, the data that that could be extracted from the companies (through specific APIs) for research is significantly reduced, and while companies continue to exploit human-generated content and metadata in various ways for business, researchers are increasingly unable to see what is happening. Also, the kind of data that is shared is more suited for company and market research, and not for social sciences research.
Acker and Donovan sketch out the possibilities of research and data craft41 for researchers, which relies on using a combination of metrics, metadata and recommendation engines used by companies, which can also be used by researchers especially in relation to disinformation campaigns. This could be research that pushes for the companies’ accountability and to ensure that “the future of technology is bound up with the societal values of democracy, fairness, equality, and justice.”42
Even as content moderation becomes increasingly opaque and impersonal, the way we experience censorship and speech, expression and silencing remain acutely ideological and sensitive. The person whose post is removed from Facebook who is sharing a video of young girls chanting for freedom in Kashmir experiences the repeated removal and the inability of the video to remain online as a move to stamp out the Kashmiri resistance and their self-determination. Or the Dalit woman whose article on Twitter appears as “sensitive” material that you can only view on clicking experiences this as obscuring if not removal of her content online. Or the woman from Pietermaritzburg who finds that the images of traditional cultural gatherings such as the Reed Dance are censored online experiences it as persecution, and says “It’s almost like we’ve been told that we have to cover up, that we are backward.”43
How algorithms work is akin to formal procedure that is blunt and a general imposition, and though they could even respond with more immediacy and specificity than the law, computational methods are not sophisticated enough yet to ensure that algorithms are accurate and just.44 Traditional adjudicatory measures such as the courtroom had to be public, and though this did not mean that their decisions were always fair or even more accurate than those of companies, what is being put in its place is opacity – a black box instead of a black screen.
And inside the “decision factory” of content moderation, on the one side we have humans, their ingrained prejudices and the exhaustion of their labours, and on the other side are algorithms and (not) sophisticated computational and deep learning models that learn largely from the assumptions and biases that humans have, and then reproduce them on a massive scale. What we need is an exploded view45 of what is happening within content moderation.
Inside the “decision factory” of content moderation, on the one side we have humans, their ingrained prejudices and the exhaustion of their labours, and on the other side are algorithms and (not) sophisticated computational and deep learning models...
Thanks to Vijeta Kumar for talking about her experiences, Pooja Pande from Khabhar Lahariya for clarifications, Tigist Shewarega Hussen and Lori Nordstorm for comments, copyedits and suggestions.
1 In a session on transparency reports at Rights Con 2019 in Tunisia, the spokesperson for Facebook when asked a question about how are content moderators treated, said that it has no relevance to the question of efficacy of transparency reports.
2 Roberts, S. (2016). Digital Refuse: Canadian Garbage, Commercial Content Moderation and the Global Circulation of Social Media’s Waste. Media Studies Publications. 14. https://ir.lib.uwo.ca/commpub/14
3 Irani, L. (2016). The Hidden Faces of Automation. XRDS Vol 23. No.2.
4 Ibid.
5. Nakamura, L. (2015). “The Unwanted Labour of Social Media: Women of Color Call Out Culture as Venture Community Management”. New Formations: a journal of culture, theory, politics. 106-112.
6 In a presentation Tigist Shewarega Hussen refers to the uberisation of feminism, particularly to how local movements are replaced but this metaphor also gestures to how labour is gendered and appropriated within movements as well. Hussen T. (2019). Iceland #metoo conference(name?).
7 Hampton, R. (23 April 2019). The Black Feminists Who Saw the Alt-Right Threat Coming. The Slate. https://slate.com/technology/2019/04/black-feminists-alt-right-twitter-gamergate.html
8 Terranova, T. (2000) Free Labour: Producing Culture for the Digital Economy. Social Text 18 (63). http://doi.org/fp8tzw
9 Nakamura, L. (2015). Op. cit. See also Gajjalla, R. (23 February 2017). The problem of value for "women's work". GenderIT: Editorial. https://www.genderit.org/node/4907/
10 Shorey, S., Howard, P. (2016). Automation, Big Data, and Politics: A Research Review. International Journal of Communication.
11 Costanza-Chock, S. (16 July 2018). Design Justice, A.I., and Escape from the Matrix of Domination, Journal of Design and Science. MIT Media Lab https://doi.org/10.21428/96c8d426; See also the Design Justice Network Principles that state - “We center the voices of those who are directly impacted by the outcomes of the design process.”
12 Ganesh, M. (28 June 2019). You auto-complete me: romancing the bot. DeepDives. https://deepdives.in/you-auto-complete-me-romancing-the-bot-f2f16613fec8
13 YouTube Community Guidelines enforcement https://transparencyreport.google.com/youtube-policy/removals
14 Facebook Transparency: Community Standards Enforcement Report https://transparency.facebook.com/community-standards-enforcement
15 Most of what Youtube removed if broken down is spam, scams or misleading content (69.2%), nudity and pornography (13%), child safety (9.5%), and the rest, which is only 2.9%, is violent or graphic content.
16 Caplan, R. (14 November 2018). Content or context moderation: Artisanal, Community-Reliant, and Industrial Approaches. https://datasociety.net/output/content-or-context-moderation/
17 To see the tip of the problem of how right-wing propaganda spreads virally and is heatedly defended, you can explore this tracker of the abuse on Twitter that women journalists in India received in 2017. https://www.hindustantimes.com/interactives/lets-talk-about-trolls/whats-it-like-to-get-trolled-all-day-long/
18 Caplan interviewed representatives of platform companies, both large and small, from a variety of positions on their policy and technology teams. Caplan, R. (14 November 2018). Op. cit.
19 A/HRC/17/31.
20 Special Rapporteur on Freedom of Opinion and Expression. (6 April 2018).Report of the Special Rapporteur on the promotion and protection of the right to freedom of opinion and expression. A/HRC/38/35. https://ap.ohchr.org/documents/dpage_e.aspx?si=A/HRC/38/35
21 Kaye, D. (25 June 2019). A New Constitution for Content Moderation. OneZero. https://onezero.medium.com/a-new-constitution-for-content-moderation-6249af611bdf
22 Hampton, R. (23 April 2019). Op. cit.
23 Acker A., Donovan, J. (2019): Data craft: a theory/methods
package for critical internet studies, Information, Communication & Society, DOI:
10.1080/1369118X.2019.1645194
24 Chaturvedi. S. (2016). I am a troll: inside the secret world of BJP’s digital army. Juggernaut.
25 For a discussion on how fake accounts can be discovered through automation see J Paavola, Helo, Jalonen H., Sartonen, M., Huhtinen A-M. (2016). Understanding the Trolling Phenomenon: The Automated Detection of Bots and Cyborgs in the Social Media. Journal of Information Warfare Vol. 15. Issue 4.
26 Paavola, J., Helo, T., Jalonen, H., Sartonen M., Huhtinen A-M. )2016) Understanding the Trolling Phenomenon: The Automated Detection of Bots and Cyborgs in the Social Media. Journal of Information Warfare Vol. 15, Issue 4.
27Roberts. S. (March, 2018). “Digital detritus: ‘Error’ and the logic of opacity in social media content moderation.” First Monday: peer-reviewed journal on the internet. Vol. 23. Number 3-5. https://firstmonday.org/ojs/index.php/fm/article/view/8283/6649
28 Aruna, S. (21 November 2019). My poster in Jack Dorsey's hands wasn't the point; real threat to trolls was me seeking safety of oppressed on Twitter. First Post. https://www.firstpost.com/india/my-poster-in-jack-dorseys-hands-wasnt-the-point-real-threat-to-trolls-was-me-seeking-safety-of-oppressed-on-twitter-5590901.html
29 Semmalar, G.I. (2019). Okay Nandini Krishnan, I read your book Invisible Men and here’s why it’s offensive. The News Minute. https://www.thenewsminute.com/article/okay-nandini-krishnan-i-read-your…
30 Kumar, V. (25 Jan 2019). For Rohith Vemula, who wanted to learn, but ended up taking his own life; and for Savarnas who are too good to learn. Firstpost. https://www.firstpost.com/india/for-rohith-vemula-who-wanted-to-learn-and-for-savarnas-who-are-too-good-to-learn-5920051.html
31 Presentation by Khabhar Lahariya. (2019). Imagine a Feminist Internet. Forthcoming publication.
32 Paavola, J., Helo, T., Jalonen, H., Sartonen M., Huhtinen A-M. (2016). Op. cit.
33 Kuhn, A. (1988). Cinema, Censorship, and Sexuality, 1909-1925. Routledge.
34 Arora, P. (1995). “Imperilling the Prestige of the White Woman”: Colonial Anxiety and Film Censorship in British India. Visual Anthropology Review. https://doi.org/10.1525/var.1995.11.2.36
35 Prasad, M. (1998). Ideologyof the Hindi film. Northwestern University.
36 Aavriti, N. (2011). Porn: law, video and technology. Center for Internet and Society.
37 Shah, N. (2007). ‘Subject to Technology: Internet Pornography, Cyber-terrorism and the Indian State’, InterAsia Cultural Studies, 8:3.
38 Gopinath. G. (2005). Impossible Desires: Queer Diasporas and South Asian Public Cultures. Duke University Press.
39 Ranjit D. Udeshi v. State of Maharashtra. 1965 AIR 881. The disintegration of how censorship controls consumption had already started happening with television and video, particularly cable TV.
40 Shorey, S., Howard, P. (2016). Op. cit.
41 Acker A., Donovan, J. (2019): Data craft: a theory/methods package for critical internet studies, Information, Communication & Society, DOI: 10.1080/1369118X.2019.1645194
42 Acker, A, Donovan, J. (2019). Op. cit.
44 This refers to the differences between law and justice, and how law is often procedure that is the incomplete promise of justice. Derrida J. (1992) Force of law: the metaphysical foundation of authority. Deconstruction and the possibility of justice (Eds: Cornell. Rosenfeld. Carson). Routledge.
45 Kate Crawford’s remarkable breaking down of the visual anatomy of AI shows the multitudes of tiny decisions, extractions and layers that go into a simple voice command to a device. Would it even be possible to similarly understand content moderation, and how humans too are programmed and hard-wired in certain ways? See Crawford, K. Joler, V. (2018). Anatomy of an AI system. https://anatomyof.ai/
- 9910 views

Add new comment